Details
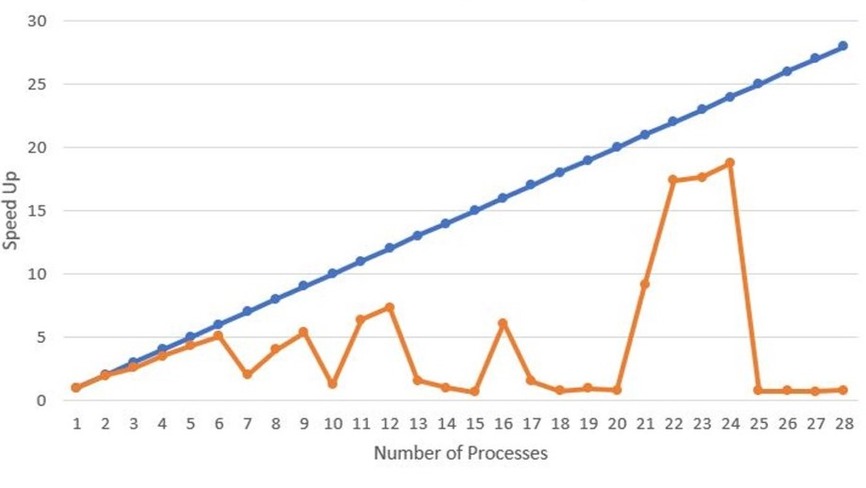
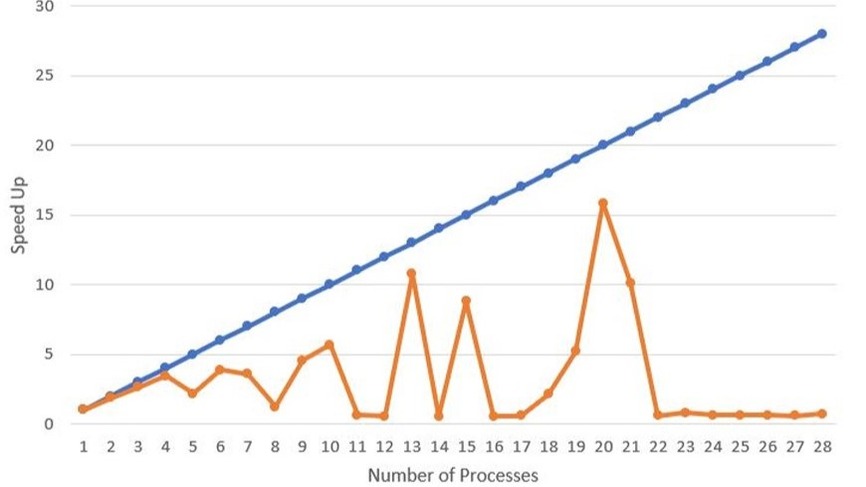
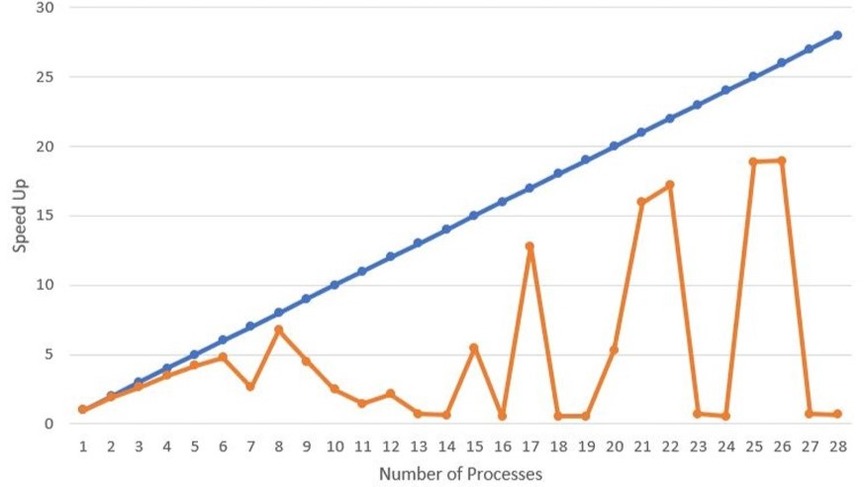
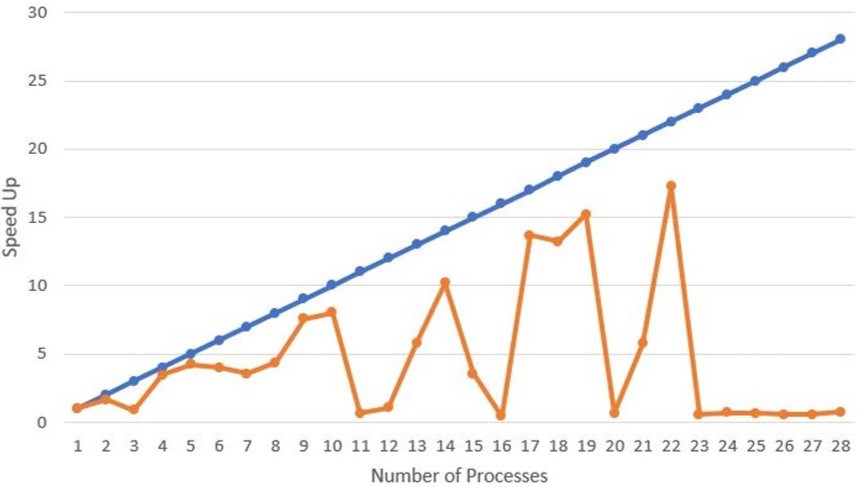
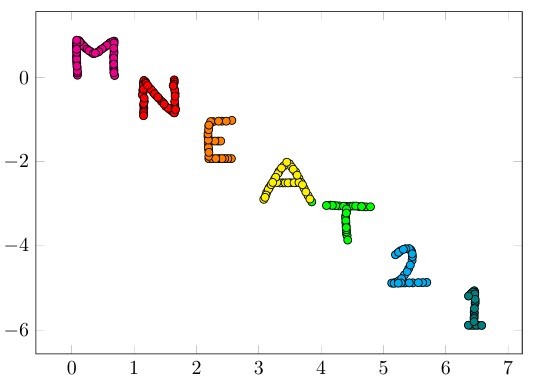
This project was the accumulation and compilation of skills I learned including learning C++, writing my own version of Lloyd's k-Means algorithm, checking memory issues with Valgrind, using MPI and CUDA to parallelize the code to improve efficiency, and experimenting with optimization flags. The first table illustrates the speed up using two different compilers with different optimization flags. The graphs below illustrate the results of a strong scaling study identifying the speed up ratio: Number of MPI processes vs Speed up (T1 / Tp) with T1 being time for one processor and Tp being the time for T processors. The blue line is the theoretical perfect speed up rate and the orange line is the measured value. This was run on the Virginia Tech Cascade compute cluster to access higher end computing as I unfortunately do not own a computer with 28+ cores. I have also included one of the simple datasets for testing my k-Means algorithm script. You can see each symbol in mneat21 is a separate cluster. There is one point that is misclassified but uh don't look at that. The code for this and more of my work with k-Means and parallel coding can be found on my github.
Results
| Optimization | Compiler | Runtime (seconds) | Speedup |
|---|---|---|---|
| None | mpicc | 0.005514 | 1 |
| -O1 | mpicc | 0.001406 | 3.92176 |
| -O2 | mpicc | 0.001324 | 4.16465 |
| -O3 | mpicc | 0.001277 | 4.31793 |
| None | icpc | 0.006201 | 0.8892 |
| -O1 | icpc | 0.001810 | 3.0464 |
| -O2 | icpc | 0.001796 | 3.070155 |
| -O3 | icpc | 0.001764 | 3.125850 |